Boutique Knowledge Graphs: Creating Smart Content at Any Scale
A knowledge graph is a collection of real world facts whose properties and relationships are described in ways that machines can process. Knowledge graphs help computers infer new information that, though it is not explicitly stated in any one data source, is necessarily true given all the facts combined.
Knowledge graphs can capture data about just about anything: products, services, how-tos, and fact sheets are all common use cases. These kinds of data facts are how a search query for “gluten free delivery near me” can return a map of your area and a list of restaurants. Even though the facts about your location, a restaurant’s menu, and whether they (or another service) will deliver food may all come from different sources, when those facts and their relationships are machine readable, a search algorithm is able to provide an answer to your “question” (even though that answer isn’t explicitly published in any one place—and in this case, even though you didn’t even mention “food”).
Search provides just one example of the kinds of interactions knowledge graphs can support. Knowledge graphs also play an increasingly important role in many other industries that grapple with large amounts of information and complexity. Biotech, telecom, finance, and cybersecurity all use knowledge graphs to derive new information from existing data to solve business and user problems.
Though global corporations and search giants offer the most prominent examples, the benefits of knowledge graphs are not limited to enterprise use cases. The situation of data in context that knowledge graphs provide opens up new opportunities for content personalization and recommendations, content creation, semantic search, and enhanced analytics that can be used by organizations of any size—including those starting out small and seeking to solve a few well-defined communication and discovery problems. I refer to these kinds of applications as “boutique knowledge graphs.”
The Upside to Starting Small
Unlike traditional “monolithic” enterprise IT solutions, knowledge graph technologies invite what Dave McComb of Semantic Arts calls a “start small, think big” approach. Two key features of knowledge graphs make this possible:
- Foundational knowledge graph technologies are built on open W3C semantic web standards. Many of the tools that power enterprise-ready software suites are built on a foundation of the same technologies that anyone can use to set up a boutique knowledge graph.
- W3C semantic web standards are designed to work at any scale—and to remain effective whether you’re marshaling 200 facts or 2 billion facts. Projects at either end of this spectrum will have very different infrastructure needs, but the data and relationships represented in each case use the same underlying data model (RDF).
Cost, both in terms of financial outlay and the organizational effort needed to stand up an enterprise system, is a common roadblock to beginning work on a knowledge graph. A boutique knowledge graph is a way to start small—and return actual value. This is an appealing approach for many orgs who want to “test the waters” before diving in.
Starting small, however, should not be considered a second tier solution. As systems theorist John Gall puts it, “A large system that works is invariably composed of smaller systems that work.” Because of the knowledge graph’s innate ability to scale and its foundation in shared tools, beginning with these smaller systems is often a better choice overall.
Boutique Knowledge Graph Design Principles
Knowledge graphs have been the subject of an increasing amount of attention in the last couple years, which has led to a flood of interpretations of what they can do and how to set them up. No single set of heuristics will cover every use case, but if you’re looking for a way to start small, deliver value, and build a foundational system that will work (and work as it scales), the following design principles, drawn from my own experience with client projects, content, and information needs, are a good place to start:
- Use standards
The temptation to adopt ad hoc or convenient but proprietary data formats can be strong. Standardized data models—such as RDF, SKOS, and OWL—make data more interoperable and more readily reusable. The little bit of up front effort to adopt standards can save hours and days of headaches later. - Use unique identifiers
Knowledge graphs combine data from different sources. Ensuring that each data point—each fact—can be uniquely identified is crucial to maintaining the integrity of the combined data set as it scales. - Structure content for reuse
Humans excel at extracting facts from blocks of text and other potentially ambiguous formats. In order for machines to do so, that text must first be parsed by natural language processing tools. Even with this extra step, the margin of error in the data returned can be shockingly high. Well structured content describes the facts content communicates and the relationships between those facts in ways that both humans and machines can directly understand. - Address business needs from the outset
Knowledge graphs, like taxonomies, can be built for a purpose, or of a subject. When building for a purpose, it is much easier to determine what should be built, identify when it is done, and evaluate the degree to which it is effective. Building a graph representation “of a subject” may have no realistic endpoint, and may deliver value sporadically, if at all. - Always think about the next larger context
To quote architect Eliel Saarinen, “Always design a thing by considering it in its next larger context—a chair in a room, a room in a house, a house in an environment, an environment in a city plan.” Keeping in mind the next larger context is why we use standards, unique identifiers, and structured content: each of these anticipates the way the data we capture in the moment will interact with the larger data environment in which it is situated.
A Boutique Knowledge Graph in Action
While I’m not at liberty to share examples from client work of these principles in action (for all the usual privacy reasons), a recent redesign of a personal project offers a practical view of how a boutique knowledge graph can add value to a content-focused project at a small scale.
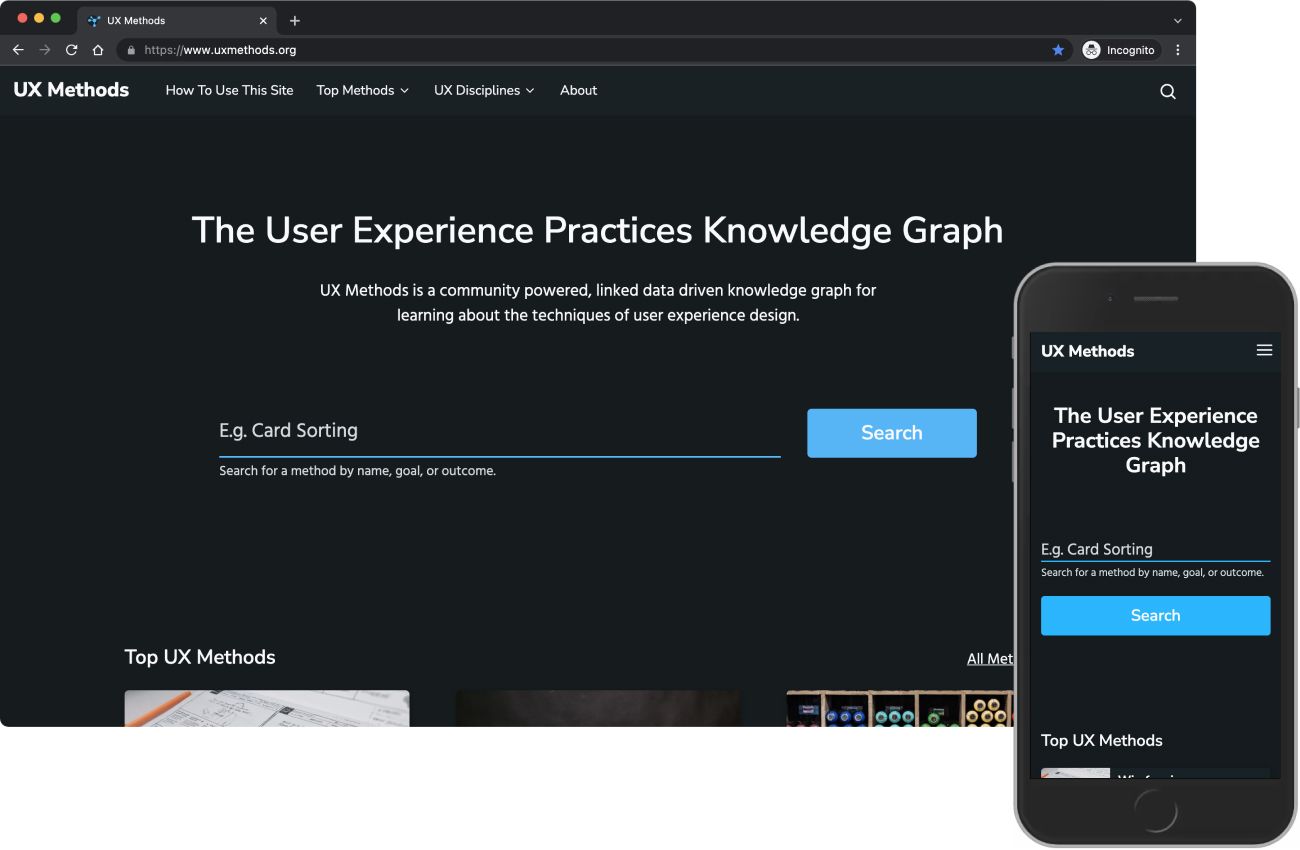
UXMethods.org is a collection of how-tos and web resources aimed at helping UX practitioners more easily discover and connect UX processes and tools. UX Methods combines structured content, open source semantic web technologies, and cloud-based graph data management to create and use a loosely-coupled, goal-focused knowledge graph.
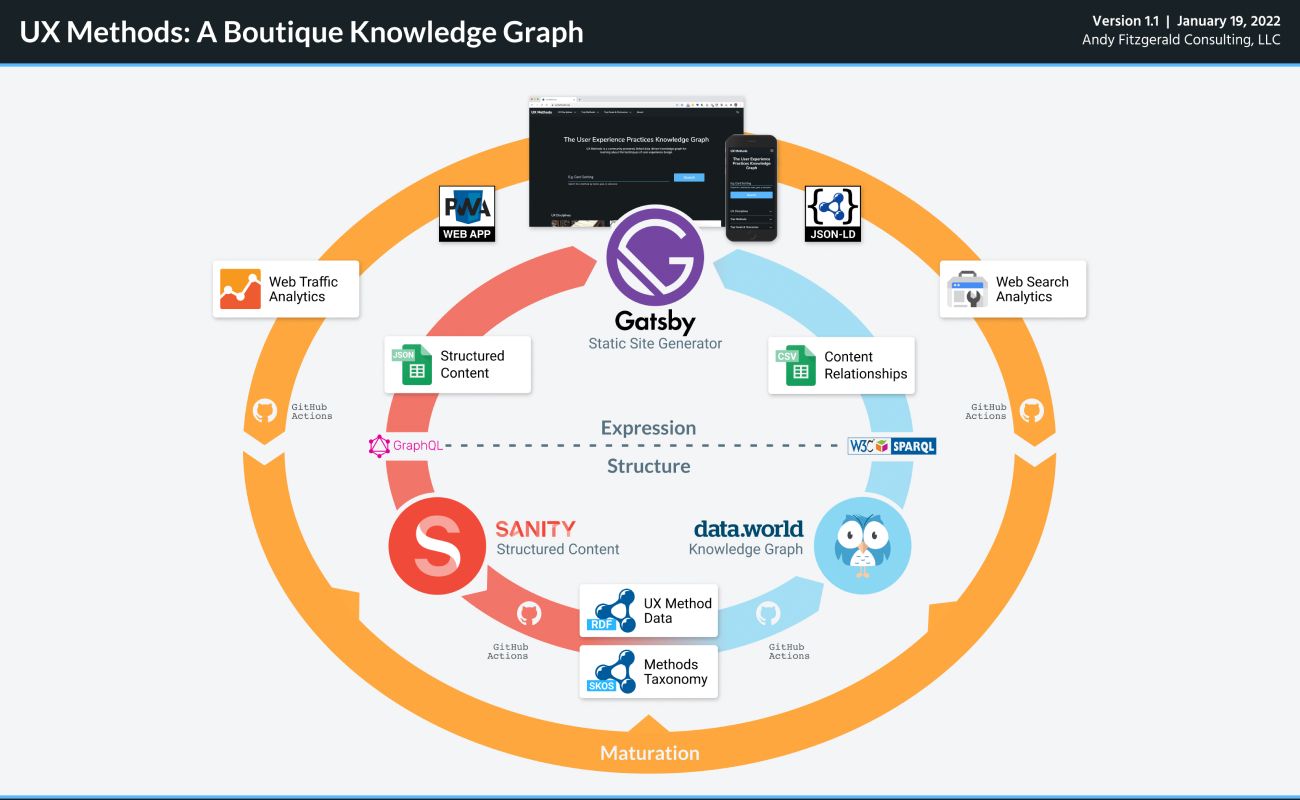
Key components of the UX Methods information ecosystem include:
- Sanity CMS: A fully decoupled headless CMS that gives content designers wide latitude over the structure and composition of content. Initial UX Methods content types include Methods, Disciplines, and Web Resources (links and metadata about external sites that provide additional information about methods, tools, and approaches).
- data.world: A cloud-native, graph-based data catalogue. data.world provides APIs for programmatically importing and combining data, and SPARQL endpoints for running aggregated queries across data sets.
- Gatsby: A React-based open source framework for building static JAMStack websites that draw from multiple data sources.
- GitHub Actions: A repository-integrated CI/CD workflow automation toolkit.
- For details on how to use Structure, Expression, and Maturation concepts to coordinate structured content driven information ecosystems, check out Structured Content Design Workflow 2022.
Even in this narrow and very small scale example, we can find some examples of how the principles above help make for “small systems that work”—and set those systems up to scale to much broader capabilities and capacities:
Using Standards
In UX Methods, structured content from Sanity is turned into semantic graph content prior to the site being built in Gatsby. This process serializes Methods content from Sanity’s API as RDF triples (.ttl) and writes them to data.world. A parallel process serializes input/output taxonomy content as SKOS and writes it to a linked dataset.
UX Methods currently doesn’t make use of SKOS synonyms or broader terms in recommending and ranking content, but by basing this initial implementation on the SKOS standard, a number of modeling and labeling questions are taken care of automatically, and the taxonomy is already set to scale as additional features are added.
Use of Unique Identifiers
The UX Methods Gatsby build process uses content data from two source APIs: the Sanity headless CMS, and inferred graph data from data.world. Sanity provides structured content and assets; data.world provides ranking and recommendation data. In each case, Methods are identified by a unique URI in the format https://uxmethods.org/method/<method>. This allows each process to identify and correlate the appropriate content values, assets, and data.
Unique identifiers also pave the way for future integrations. Currently, web traffic and search console data is not being programmatically incorporated into the build process or generation of recommendations. Since those values are all keyed to stable and identifiable URIs, however, once there is enough content to warrant the extra level of nuance, integrating that data will follow a predictable set of steps.
Structuring Content for Reuse
The structured content designed and authored in Sanity provides “content as data” that is used in several different ways in the build process of UX Methods:
- Content data is used to produce “Methods” resources, available to site visitors at the method URI
- Content data is used to populate the knowledge graph at data.world, which is subsequently used to generate “preparation” and “next steps” recommendations
- Structured content and graph data are used in combination to generate schema.org JSON-LD data, which helps search algorithms parse and index content for search results, rich snippets, and smart agent consumption
Addressing Business Needs from the Outset
The knowledge graph backing UX Methods is designed to accomplish two specific tasks: generate recommendations for Method preparation and Method next steps, and generate a prioritized list of “Top Methods” for ranking home page navigation links and weighting search results. These goals simplified the process of designing the taxonomy needed to support the knowledge graph by outlining clear objectives with measurable success metrics
Thinking About the Next Larger Context
Delivering measurable value by addressing business needs early on in the process of developing a knowledge graph need not preclude designing a system that scales. This is one of the unique properties of knowledge graphs that sets them apart from traditional “monolithic” enterprise software. For UX Methods, there are several “larger contexts” which these humble beginnings set it up to support:
- Elevation of external “web resources” to fully defined objects
Right now, external Web Resources are “strings” in the build process, rather than uniquely identifiable “things” in the knowledge graph. A first “next larger context” is to more fully define the additional elements beyond Methods and Disciplines in the UX Methods domain. This context is supported by the existing implementation’s use of standards and unique identifiers and its reuse-ready structured content. - Expanded application of the UX Methods Input/Output taxonomy
The Input/Output taxonomy currently uses only a single hierarchical level to classify content. Extending classification to include parent-child relationships between concepts will allow more nuanced classification and discovery as the UX Methods content set grows. The taxonomy’s SKOS data model paves the way for these more expressive structures. - Publication of the knowledge graph for broader use
The UX Methods knowledge graph is already published for use beyond the UX Methods website as JSON-LD, which makes UX Methods content easier to parse by search algorithms and smart agents (like smart home voice assistants). A larger context of reuse and interoperability involves publishing knowledge graph resources as RDF that supports HTTP content negotiation. This will allow UX Methods data to be integrated in and across other knowledge graph applications on the web.
Balancing Utility and Growth
When you shift mindset from the “idea of standing up a knowledge graph” in the abstract to focusing on what outcomes you need to accomplish, it becomes much easier to scope what your knowledge graph needs to support—and to dispassionately ask whether you actually need a knowledge graph at all.
Thanks to the openness of semantic web standards and the inherent scalability of knowledge graph techniques, “thinking big while starting small” with a boutique knowledge graph can be a sensible way to begin to realize the benefits of this rapidly emerging technology.
Learn More
There is a lot of content about knowledge graph design, implementation, and use out there, much of it related to particular products and services. While many of these sources offer unique insights into particular use cases, it can be difficult to find neutral sources that focus on producing functional implementations centered on the open W3C standards. Here is a short list of resources I’ve found particularly valuable that offer a good starting point for those new to knowledge graph design and implementation:
- “Knowledge Graphs,” OpenHPI (free self-paced online course, 6 weeks)
- Semantic Web for the Working Ontologist, Dean Allemang, James Hendler, and Fabien Gandon
- Demystifying OWL for the Enterprise, Michael Uschold
- Learning SPARQL, Bob DuCharme
- Bob DuCharme’s blog, “mostly on technology for representing and linking information”
- Designing Connected Content, Carrie Hane and Mike Atherton
- “Content Modelling: A Master Skill,” Rachel Lovinger
- “Structured Content Design Workflow 2022,” Andy Fitzgerald